MCS-041, MCS-042, MCS-043, MCS-044, MCSL-045


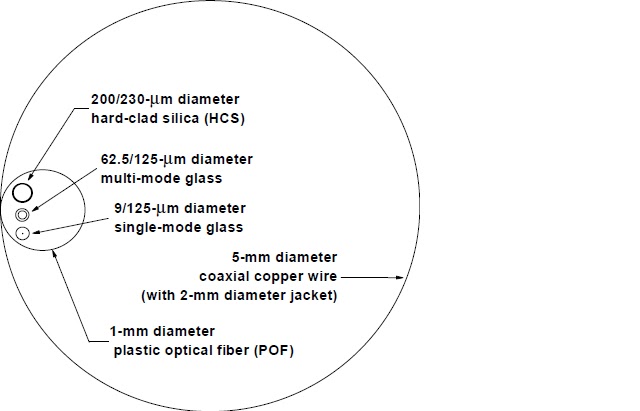
• BANDWIDTH: large carrying capacity
• DISTANCE: Signals can be transmitted further without needing to be "refreshed" or strengthened.
• RESISTANCE: Greater resistance to electromagnetic noise such as radios, motors or other nearby cables.
• MAINTENANCE: Fiber optic cables costs much less to maintain.
Question 1:
State the Readers and Writers problem and
write its semaphore based solution. Also describe the algorithm. Can the producer consumer problem be
considered as a special case of Reader/Writer problem with a single Writer (the
producer) and a single Reader (consumer)?. Explain.
(20
Marks)
Answer:
The readers/writers problem is one of the classic synchronization problems. It is often used to
compare and contrast synchronization mechanisms. It is also an eminently used practical
problem. A common paradigm in concurrent applications is isolation of shared data such as a
variable, buffer, or document and the control of access to that data.
This problem has two types of clients accessing the shared data. The first type, referred to as
readers, only wants to read the shared data. The second type, referred to as writers, may want to
modify the shared data.
There is also a designated central data server or controller. It enforces exclusive write semantics;
if a writer is active then no other writer or reader can be active. The server can support clients that
wish to both read and write. The readers and writers problem is useful for modelling processes
which are competing for a limited shared resource.
Semaphores can be used to restrict access to the database under certain conditions. In this
example, semaphores are used to prevent any writing processes from changing information in the
database while other processes are reading from the database.
semaphore mutex = 1; //Controls access to the reader count
semaphore db = 1; //Controls access to the database
int reader_count; //The number of reading processes accessing the data
Reader()
{
while (TRUE) { // loop forever
down(&mutex); //gain access to reader_count
reader_count = reader_count + 1; //increment the reader_count
if (reader_count == 1)
down(&db); //If this is the first process to read the database,
// d down on db is executed to prevent access to the
// database by a writing process
up(&mutex); //allow other process to access reader_count
read_db(); //read the database
down(&mutex); // gain access to reader_count
reader_count = reader_count – 1; //decrement reader_count
if(reader_count == 0)
up(&db); //if there are no more processes reading from the
//database, allow writing process to access the data
up(&mutex); //allow other processes to access
reader_countuse_data(); //use the data read from the database (non-critical)
}
Writer()
{
while(TRUE) { // loop forever
create_data(); // create data to enter into database (non-critical)
down(&db); // gain access to the database
write_db(); // write information to the database
up(&db); // release exclusive access to the database
}
The readers/writers problem is one of the classic synchronization problems. It is often used to
compare and contrast synchronization mechanisms. It is also an eminently used practical
problem. A common paradigm in concurrent applications is isolation of shared data such as a
variable, buffer, or document and the control of access to that data.
This problem has two types of clients accessing the shared data. The first type, referred to as
readers, only wants to read the shared data. The second type, referred to as writers, may want to
modify the shared data.
There is also a designated central data server or controller. It enforces exclusive write semantics;
if a writer is active then no other writer or reader can be active. The server can support clients that
wish to both read and write. The readers and writers problem is useful for modelling processes
which are competing for a limited shared resource.
Semaphores can be used to restrict access to the database under certain conditions. In this
example, semaphores are used to prevent any writing processes from changing information in the
database while other processes are reading from the database.
semaphore mutex = 1; //Controls access to the reader count
semaphore db = 1; //Controls access to the database
int reader_count; //The number of reading processes accessing the data
Reader()
{
while (TRUE) { // loop forever
down(&mutex); //gain access to reader_count
reader_count = reader_count + 1; //increment the reader_count
if (reader_count == 1)
down(&db); //If this is the first process to read the database,
// d down on db is executed to prevent access to the
// database by a writing process
up(&mutex); //allow other process to access reader_count
read_db(); //read the database
down(&mutex); // gain access to reader_count
reader_count = reader_count – 1; //decrement reader_count
if(reader_count == 0)
up(&db); //if there are no more processes reading from the
//database, allow writing process to access the data
up(&mutex); //allow other processes to access
reader_countuse_data(); //use the data read from the database (non-critical)
}
Writer()
{
while(TRUE) { // loop forever
create_data(); // create data to enter into database (non-critical)
down(&db); // gain access to the database
write_db(); // write information to the database
up(&db); // release exclusive access to the database
}
Question 2:
Describe different schemes for deadlock
prevention, avoidance and detection with major advantages and disadvantages of
each scheme.
(10
Marks)
Deadlock
Prevention:
As per Havender’s algorithm, since all four of the conditions are necessary for deadlock to occur, it follows that deadlock might be prevented by denying any one of the conditions.
Havender’s Algorithm
Elimination of “Mutual Exclusion” Condition
The mutual exclusion condition must hold for non-shareable resources. That is several processes cannot simultaneously share a single resource. This condition is difficult to eliminate because some resources, such as the tap drive and printed, are inherently non-shareable. Note that shareable resources like read-only-file do not require mutually exclusive access and thus cannot be involved in deadlock.
Elimination of “Hold and Wait” Condition
There are two possibilities for the elimination of the second condition. The first alternative is that a process request be granted all the resources it needs at once, prior to execution. The second alternative is to disallow a process from requesting resources whenever it has previously allocated resources. This strategy requires that all the resources a process will need must be requested at once. The system must grant resources on “all or none” basis. If the complete set of resources needed by a process is not currently available. While the process waits, however, it may not hold any resources. Thus the “wait for” condition is denied and deadlocks simply cannot occur. This strategy can lead to serious waste of resources.
For example, a program requiring ten tape drives must request and receive all ten drives before it begins executing. If the program needs only one tape drive to begin execution and then does not need the remaining tape drives for several hours then substantial computer resources (9 tape drivers) will sit idle for several hours. This strategy can cause indefinite postponement (starvation), since not all the required resources may become available at once.
Elimination of “No-pre-emption” Condition
The non-pre-emption condition can be alleviated by forcing a process waiting for a resource that cannot immediately be allocated, to relinquish all of its currently held resources, so that other processes may use them to finish their needs. Suppose a system does allow processes to hold resources while requesting additional resources. Consider what happens when a request cannot be satisfied. A process holds resources a second process may need in order to proceed, while the second process may hold the resources needed by the first process. This is a deadlock. This strategy requires that when a process that is holding some resources is denied a request for additional resources, the process must release its held resources and, if necessary, request them again together with additional resources. Implementation of this strategy denies the no-preemptive” condition effectively.
High Cost
When a process releases resources, the process may lose all its work to that point. One serious consequence of this strategy is the possibility of indefinite postponement (starvation). A process might be held off indefinitely as it repeatedly requests and releases the same resources.
Elimination of “Circular Wait” Condition
The last condition, the circular wait, can be denied by imposing a total ordering on all of the resource types and than forcing all processes to request the resources in order (increasing or decreasing). This strategy imposes a total ordering of all resource types, and requires that each process requests resources in a numerical order of enumeration. With this rule, the resource allocation graph can never have a cycle.
This strategy, if adopted, may result in low resource utilisation and in some cases starvation is possible too.
Deadlock Avoidance:
This approach to the deadlock problem anticipates a deadlock before it actually occurs. This approach employs an algorithm to access the possibility that deadlock could occur and act accordingly. This method differs from deadlock prevention, which guarantees that deadlock cannot occur by denying one of the necessary conditions of deadlock. The most famous deadlock avoidance algorithm, from Dijkstra [1965], is the Banker’s algorithm. It is named as Banker’s algorithm because the process is analogous to that used by a banker in deciding if a loan can be safely made or not.
The Banker’s Algorithm is based on the banking system, which never allocates its vailable cash in such a manner that it can no longer satisfy the needs of all its customers. Here we must have the advance knowledge of the maximum possible claims for each process, which is limited by the resource availability. During the run of the system we should keep monitoring the resource allocation status to ensure that no circular wait condition can exist.
If the necessary conditions for a deadlock are in place, it is still possible to avoid deadlock by being careful when resources are allocated. The following are the features that are to be considered for avoidance of the deadlock as per the Banker’s Algorithms.
• Each process declares maximum number of resources of each type that it may need.
• Keep the system in a safe state in which we can allocate resources to each process in
some order and avoid deadlock.
• Check for the safe state by finding a safe sequence: < P1, P2, …, Pn > where resources
that Pi needs can be satisfied by available resources plus resources held by Pj where j < i.
• Resource allocation graph algorithm uses claim edges to check for a safe state. The resource allocation state is now defined by the number of available and allocated resources, and the maximum demands of the processes. Subsequently the system can be in either of the following states:
• Safe State: Such a state occur when the system can allocate resources to each process (up to its maximum) in some order and avoid a deadlock. This state will be characterised by a safe sequence. It must be mentioned here that we should not falsely conclude that all unsafe states are deadlocked although it may eventually lead to a deadlock.
• Unsafe State: If the system did not follow the safe sequence of resource allocation from the beginning and it is now in a situation, which may lead to a deadlock, then it is in an unsafe state.
• Deadlock State: If the system has some circular wait condition existing for some
processes, then it is in deadlock state.
It is important to note that an unsafe state does not imply the existence or even the eventual existence of a deadlock. What an unsafe state does imply is simply that some unfortunate sequence of events might lead to a deadlock.
The Banker’s algorithm is thus used to consider each request as it occurs, and see if granting it leads to a safe state. If it does, the request is grated, otherwise, it is postponed until later.
Limitations of the Banker’s Algorithm:
• It is time consuming to execute on the operation of every resource.
• If the claim information is not accurate, system resources may be underutilised.
• Another difficulty can occur when a system is heavily loaded. Lauesen states that in this situation “so many resources are granted away that very few safe sequences remain, and as a consequence, the jobs will be executed sequentially”. Therefore, the Banker’s
algorithm is referred to as the “Most Liberal” granting policy; that is, it gives away
everything that it can without regard to the consequences.
• New processes arriving may cause a problem.
o The process’s claim must be less than the total number of units of the resource in the system. If not, the process is not accepted by the manager.
o Since the state without the new process is safe, so is the state with the new process. Just use the order you had originally and put the new process at the end.
o Ensuring fairness (starvation freedom) needs a little more work, but isn’t too hard
either (once every hour stop taking new processes until all current processes finish).
• A resource becoming unavailable (e.g., a tape drive breaking), can result in an unsafe
state.
Deadlock Detection:
Detection of deadlocks is the most practical policy, which being both liberal and cost efficient, most operating systems deploy. To detect a deadlock, we must go about in a recursive manner and simulate the most favoured execution of each unblocked process.
• An unblocked process may acquire all the needed resources and will execute.
• It will then release all the acquired resources and remain dormant thereafter.
• The now released resources may wake up some previously blocked process.
• Continue the above steps as long as possible.
• If any blocked processes remain, they are deadlocked.
As per Havender’s algorithm, since all four of the conditions are necessary for deadlock to occur, it follows that deadlock might be prevented by denying any one of the conditions.
Havender’s Algorithm
Elimination of “Mutual Exclusion” Condition
The mutual exclusion condition must hold for non-shareable resources. That is several processes cannot simultaneously share a single resource. This condition is difficult to eliminate because some resources, such as the tap drive and printed, are inherently non-shareable. Note that shareable resources like read-only-file do not require mutually exclusive access and thus cannot be involved in deadlock.
Elimination of “Hold and Wait” Condition
There are two possibilities for the elimination of the second condition. The first alternative is that a process request be granted all the resources it needs at once, prior to execution. The second alternative is to disallow a process from requesting resources whenever it has previously allocated resources. This strategy requires that all the resources a process will need must be requested at once. The system must grant resources on “all or none” basis. If the complete set of resources needed by a process is not currently available. While the process waits, however, it may not hold any resources. Thus the “wait for” condition is denied and deadlocks simply cannot occur. This strategy can lead to serious waste of resources.
For example, a program requiring ten tape drives must request and receive all ten drives before it begins executing. If the program needs only one tape drive to begin execution and then does not need the remaining tape drives for several hours then substantial computer resources (9 tape drivers) will sit idle for several hours. This strategy can cause indefinite postponement (starvation), since not all the required resources may become available at once.
Elimination of “No-pre-emption” Condition
The non-pre-emption condition can be alleviated by forcing a process waiting for a resource that cannot immediately be allocated, to relinquish all of its currently held resources, so that other processes may use them to finish their needs. Suppose a system does allow processes to hold resources while requesting additional resources. Consider what happens when a request cannot be satisfied. A process holds resources a second process may need in order to proceed, while the second process may hold the resources needed by the first process. This is a deadlock. This strategy requires that when a process that is holding some resources is denied a request for additional resources, the process must release its held resources and, if necessary, request them again together with additional resources. Implementation of this strategy denies the no-preemptive” condition effectively.
High Cost
When a process releases resources, the process may lose all its work to that point. One serious consequence of this strategy is the possibility of indefinite postponement (starvation). A process might be held off indefinitely as it repeatedly requests and releases the same resources.
Elimination of “Circular Wait” Condition
The last condition, the circular wait, can be denied by imposing a total ordering on all of the resource types and than forcing all processes to request the resources in order (increasing or decreasing). This strategy imposes a total ordering of all resource types, and requires that each process requests resources in a numerical order of enumeration. With this rule, the resource allocation graph can never have a cycle.
This strategy, if adopted, may result in low resource utilisation and in some cases starvation is possible too.
Deadlock Avoidance:
This approach to the deadlock problem anticipates a deadlock before it actually occurs. This approach employs an algorithm to access the possibility that deadlock could occur and act accordingly. This method differs from deadlock prevention, which guarantees that deadlock cannot occur by denying one of the necessary conditions of deadlock. The most famous deadlock avoidance algorithm, from Dijkstra [1965], is the Banker’s algorithm. It is named as Banker’s algorithm because the process is analogous to that used by a banker in deciding if a loan can be safely made or not.
The Banker’s Algorithm is based on the banking system, which never allocates its vailable cash in such a manner that it can no longer satisfy the needs of all its customers. Here we must have the advance knowledge of the maximum possible claims for each process, which is limited by the resource availability. During the run of the system we should keep monitoring the resource allocation status to ensure that no circular wait condition can exist.
If the necessary conditions for a deadlock are in place, it is still possible to avoid deadlock by being careful when resources are allocated. The following are the features that are to be considered for avoidance of the deadlock as per the Banker’s Algorithms.
• Each process declares maximum number of resources of each type that it may need.
• Keep the system in a safe state in which we can allocate resources to each process in
some order and avoid deadlock.
• Check for the safe state by finding a safe sequence: < P1, P2, …, Pn > where resources
that Pi needs can be satisfied by available resources plus resources held by Pj where j < i.
• Resource allocation graph algorithm uses claim edges to check for a safe state. The resource allocation state is now defined by the number of available and allocated resources, and the maximum demands of the processes. Subsequently the system can be in either of the following states:
• Safe State: Such a state occur when the system can allocate resources to each process (up to its maximum) in some order and avoid a deadlock. This state will be characterised by a safe sequence. It must be mentioned here that we should not falsely conclude that all unsafe states are deadlocked although it may eventually lead to a deadlock.
• Unsafe State: If the system did not follow the safe sequence of resource allocation from the beginning and it is now in a situation, which may lead to a deadlock, then it is in an unsafe state.
• Deadlock State: If the system has some circular wait condition existing for some
processes, then it is in deadlock state.
It is important to note that an unsafe state does not imply the existence or even the eventual existence of a deadlock. What an unsafe state does imply is simply that some unfortunate sequence of events might lead to a deadlock.
The Banker’s algorithm is thus used to consider each request as it occurs, and see if granting it leads to a safe state. If it does, the request is grated, otherwise, it is postponed until later.
Limitations of the Banker’s Algorithm:
• It is time consuming to execute on the operation of every resource.
• If the claim information is not accurate, system resources may be underutilised.
• Another difficulty can occur when a system is heavily loaded. Lauesen states that in this situation “so many resources are granted away that very few safe sequences remain, and as a consequence, the jobs will be executed sequentially”. Therefore, the Banker’s
algorithm is referred to as the “Most Liberal” granting policy; that is, it gives away
everything that it can without regard to the consequences.
• New processes arriving may cause a problem.
o The process’s claim must be less than the total number of units of the resource in the system. If not, the process is not accepted by the manager.
o Since the state without the new process is safe, so is the state with the new process. Just use the order you had originally and put the new process at the end.
o Ensuring fairness (starvation freedom) needs a little more work, but isn’t too hard
either (once every hour stop taking new processes until all current processes finish).
• A resource becoming unavailable (e.g., a tape drive breaking), can result in an unsafe
state.
Deadlock Detection:
Detection of deadlocks is the most practical policy, which being both liberal and cost efficient, most operating systems deploy. To detect a deadlock, we must go about in a recursive manner and simulate the most favoured execution of each unblocked process.
• An unblocked process may acquire all the needed resources and will execute.
• It will then release all the acquired resources and remain dormant thereafter.
• The now released resources may wake up some previously blocked process.
• Continue the above steps as long as possible.
• If any blocked processes remain, they are deadlocked.
Question 3:
What is thrashing? How does it happen?
When are the two mechanisms to prevent thrashing? Describe them.
(10 Marks)
Answer :
Thrashing occurs when a system spends more time processing page faults than executing
transactions. While processing page faults it is necessary to be in order to appreciate the benefits of virtual memory, thrashing has a negative effect on the system.
As the page fault rate increases, more transactions need processing from the paging device. The queue at the paging device increases, resulting in increased service time for a page fault. While the transactions in the system are waiting for the paging device, CPU utilisation, system throughput and system response time decrease, resulting in below optimal performance of a system.
Thrashing becomes a greater threat as the degree of multiprogramming of the system increases.
The two techniques for prevent thrashing are Working-Set Model and Page-Fault Rate.
Working-Set Model:
Principle of Locality
Pages are not accessed randomly. At each instant of execution a program tends to use only a small set of pages. As the pages in the set change, the program is said to move from one phase to another. The principle of locality states that most references will be to the current small set of pages in use.
Examples:
1) Instructions are fetched sequentially (except for branches) from the same page.
2) Array processing usually proceeds sequentially through the array functions repeatedly, access variables in the top stack frame.
Ramification
If we have locality, we are unlikely to continually suffer page-faults. If a page consists of 1000 instructions in self-contained loop, we will only fault once (at most) to fetch all 1000 instructions.
Working Set Definition
The working set model is based on the assumption of locality. The idea is to examine the most recent page references in the working set. If a page is in active use, it will be in the Working-set.
If it is no longer being used, it will drop from the working set.
The set of pages currently needed by a process is its working set.
WS(k) for a process P is the number of pages needed to satisfy the last k page references for process P.
WS(t) is the number of pages needed to satisfy a process’s page references for the last t units of time.
Either can be used to capture the notion of locality.
Working Set Policy
Restrict the number of processes on the ready queue so that physical memory can accommodate the working sets of all ready processes. Monitor the working sets of ready processes and, when necessary, reduce multiprogramming (i.e. swap) to avoid thrashing.
Exact computation of the working set of each process is difficult, but it can be estimated, by using the reference bits maintained by the hardware to implement an aging algorithm for pages.
When loading a process for execution, pre-load certain pages. This prevents a process from having to “fault into” its working set. May be only a rough guess at start-up, but can be quite accurate on swap-in.
Page-Fault Rate
The working-set model is successful, and knowledge of the working set can be useful for prepaging, but it is a scattered way to control thrashing. A page-fault frequency (page-fault rate) takes a more direct approach. In this we establish upper and lower bound on the desired pagefault rate. If the actual page fault rate exceeds the upper limit, we allocate the process another frame. If the page fault rate falls below the lower limit, we remove a Frame from the process. Thus, we can directly measure and control the page fault rate to prevent thrashing.
Establish “acceptable” page-fault rate.
• If actual rate too low, process loses frame.
• If actual rate too hign, process gains frame.
Thrashing occurs when a system spends more time processing page faults than executing
transactions. While processing page faults it is necessary to be in order to appreciate the benefits of virtual memory, thrashing has a negative effect on the system.
As the page fault rate increases, more transactions need processing from the paging device. The queue at the paging device increases, resulting in increased service time for a page fault. While the transactions in the system are waiting for the paging device, CPU utilisation, system throughput and system response time decrease, resulting in below optimal performance of a system.
Thrashing becomes a greater threat as the degree of multiprogramming of the system increases.
The two techniques for prevent thrashing are Working-Set Model and Page-Fault Rate.
Working-Set Model:
Principle of Locality
Pages are not accessed randomly. At each instant of execution a program tends to use only a small set of pages. As the pages in the set change, the program is said to move from one phase to another. The principle of locality states that most references will be to the current small set of pages in use.
Examples:
1) Instructions are fetched sequentially (except for branches) from the same page.
2) Array processing usually proceeds sequentially through the array functions repeatedly, access variables in the top stack frame.
Ramification
If we have locality, we are unlikely to continually suffer page-faults. If a page consists of 1000 instructions in self-contained loop, we will only fault once (at most) to fetch all 1000 instructions.
Working Set Definition
The working set model is based on the assumption of locality. The idea is to examine the most recent page references in the working set. If a page is in active use, it will be in the Working-set.
If it is no longer being used, it will drop from the working set.
The set of pages currently needed by a process is its working set.
WS(k) for a process P is the number of pages needed to satisfy the last k page references for process P.
WS(t) is the number of pages needed to satisfy a process’s page references for the last t units of time.
Either can be used to capture the notion of locality.
Working Set Policy
Restrict the number of processes on the ready queue so that physical memory can accommodate the working sets of all ready processes. Monitor the working sets of ready processes and, when necessary, reduce multiprogramming (i.e. swap) to avoid thrashing.
Exact computation of the working set of each process is difficult, but it can be estimated, by using the reference bits maintained by the hardware to implement an aging algorithm for pages.
When loading a process for execution, pre-load certain pages. This prevents a process from having to “fault into” its working set. May be only a rough guess at start-up, but can be quite accurate on swap-in.
Page-Fault Rate
The working-set model is successful, and knowledge of the working set can be useful for prepaging, but it is a scattered way to control thrashing. A page-fault frequency (page-fault rate) takes a more direct approach. In this we establish upper and lower bound on the desired pagefault rate. If the actual page fault rate exceeds the upper limit, we allocate the process another frame. If the page fault rate falls below the lower limit, we remove a Frame from the process. Thus, we can directly measure and control the page fault rate to prevent thrashing.
Establish “acceptable” page-fault rate.
• If actual rate too low, process loses frame.
• If actual rate too hign, process gains frame.
Question 4:
What are the factors important for selection
of a file organisation? Discuss three important file organisations mechanisms
and their relative performance.
(10 Marks)
Answer :
The operating system abstracts (maps) from the physical properties of its storage devices to define a logical storage unit i.e., the file. The operating system provides various system calls for file management like creating, deleting files, read and write, truncate operations etc. All operating systems focus on achieving device-independence by making the access easy regardless of the place of storage (file or device). The files are mapped by the operating system onto physical devices. Many factors are considered for file management by the operating system like directory structure, disk scheduling and management, file related system services, input/output etc. Most
operating systems take a different approach to storing information.
Three common file organisations are byte sequence, record sequence and tree of disk blocks. Unix files are structured in simple byte sequence form. In record sequence, arbitrary records can be read or written, but a record cannot be inserted or deleted in the middle of a file. CP/M works according to this scheme. In tree organisation each block hold n keyed records and a new record can be inserted anywhere in the tree. The mainframes use this approach. The OS is responsible for the following activities with regard to the file system:
• The creation and deletion of files
• The creation and deletion of directory
• The support of system calls for files and directories manipulation
• The mapping of files onto disk
• Backup of files on stable storage media (non-volatile).
A file directory is a group of files organised together. An entry within a directory refers to the file or another directory. Hence, a tree structure/hierarchy can be formed. The directories are used to group files belonging to different application/users.
The most common schemes for describing logical directory structure are:
Single-level directory
Two-level directory
Tree-structured directory
Acyclic-graph directory
General graph directory
Disk space management: The direct-access of disks and keeping files in adjacent areas of the disk is highly desirable. But the problem is how to allocate space to files for effective disk space utilisation and quick access. Also, as files are allocated and freed, the space on a disk become fragmented. The major methods of allocating disk space are:
Continuous
Non continuous (Indexing and Chaining)
The operating system abstracts (maps) from the physical properties of its storage devices to def define a logical storage unit i.e., the file. The operating system provides various system calls
The operating system abstracts (maps) from the physical properties of its storage devices to define a logical storage unit i.e., the file. The operating system provides various system calls for file management like creating, deleting files, read and write, truncate operations etc. All operating systems focus on achieving device-independence by making the access easy regardless of the place of storage (file or device). The files are mapped by the operating system onto physical devices. Many factors are considered for file management by the operating system like directory structure, disk scheduling and management, file related system services, input/output etc. Most
operating systems take a different approach to storing information.
Three common file organisations are byte sequence, record sequence and tree of disk blocks. Unix files are structured in simple byte sequence form. In record sequence, arbitrary records can be read or written, but a record cannot be inserted or deleted in the middle of a file. CP/M works according to this scheme. In tree organisation each block hold n keyed records and a new record can be inserted anywhere in the tree. The mainframes use this approach. The OS is responsible for the following activities with regard to the file system:
• The creation and deletion of files
• The creation and deletion of directory
• The support of system calls for files and directories manipulation
• The mapping of files onto disk
• Backup of files on stable storage media (non-volatile).
A file directory is a group of files organised together. An entry within a directory refers to the file or another directory. Hence, a tree structure/hierarchy can be formed. The directories are used to group files belonging to different application/users.
The most common schemes for describing logical directory structure are:
Single-level directory
Two-level directory
Tree-structured directory
Acyclic-graph directory
General graph directory
Disk space management: The direct-access of disks and keeping files in adjacent areas of the disk is highly desirable. But the problem is how to allocate space to files for effective disk space utilisation and quick access. Also, as files are allocated and freed, the space on a disk become fragmented. The major methods of allocating disk space are:
Continuous
Non continuous (Indexing and Chaining)
The operating system abstracts (maps) from the physical properties of its storage devices to def define a logical storage unit i.e., the file. The operating system provides various system calls
Question 5:
How do you differentiate between
pre-emptive and non pre-emptive scheduling? Briefly describe round robin and shortest process next scheduling with examples for each.
(10 Marks)
Answer :
CPU scheduling deals with the problem of deciding which of the processes in the ready queue is to be allocated to the CPU. A major division among scheduling algorithms is that whether they support pre-emptive or non-pre-emptive scheduling discipline.
Pre-emptive scheduling: Pre-emption means the operating system moves a process from running to ready without the process requesting it. An OS implementing these algorithms switches to the processing of a new request before completing the processing of the current request. The preempted request is put back into the list of the pending requests. Its servicing would be resumed sometime in the future when it is scheduled again. Pre-emptive scheduling is more useful in high priority process which requires immediate response. For example, in Real time system the consequence of missing one interrupt could be dangerous.
Round Robin scheduling, priority based scheduling or event driven scheduling and SRTN are considered to be the pre-emptive scheduling algorithms.
Non-Pre-emptive scheduling: A scheduling discipline is non-pre-emptive if once a process has been allotted to the CPU, the CPU cannot be taken away from the process. A non-pre-emptive discipline always processes a scheduled request to its completion. In non-pre-emptive systems, jobs are made to wait by longer jobs, but the treatment of all processes is fairer.
First come First Served (FCFS) and Shortest Job First (SJF), are considered to be the non-preemptive scheduling algorithms.
Round Robin (RR)
Round Robin (RR) scheduling is a pre-emptive algorithm that relates the process that has been waiting the longest. This is one of the oldest, simplest and widely used algorithms. The round robin scheduling algorithm is primarily used in time-sharing and a multi-user system environment where the primary requirement is to provide reasonably good response times and in general to share the system fairly among all system users. Basically the CPU time is divided into time slices.
Each process is allocated a small time-slice called quantum. No process can run for more than one quantum while others are waiting in the ready queue. If a process needs more CPU time to complete after exhausting one quantum, it goes to the end of ready queue to await the next allocation. To implement the RR scheduling, Queue data structure is used to maintain the Queue of Ready processes. A new process is added at the tail of that Queue. The CPU scheduler picks the first process from the ready Queue, Allocate processor for a specified time Quantum. After that time the CPU scheduler will select the next process is the ready Queue.
Consider the following set of process with the processing time given in milliseconds:
Process Processing Time
P1 24
P2 03
P3 03
If we use a time Quantum of 4 milliseconds then process P1 gets the first 4 milliseconds. Since it requires another 20 milliseconds, it is pre-empted after the first time Quantum, and the CPU is given to the next process in the Queue, Process P2. Since process P2 does not need 4 milliseconds, it quits before its time Quantum expires. The CPU is then given to the next process, Process P3 one each process has received 1 time Quantum, the CPU is returned to process P1 for an additional time quantum. The Gantt chart will be:
P1 P2 P3 P1 P1 P1 P1 P1
0 4 7 10 14 18 22 26 30
Process Processing Time Turn around time=t(Process Completed)- t(Process Submitted) Waiting Time=Turn around time – Processing time
P1 24 30 – 0 = 30 30 – 24 = 6
P2 03 7 – 0 = 7 7 – 3 = 4
P3 03 10 – 0 = 10 10 – 3 = 7
Average turn around time = (30+7+10)/3 = 47/3 = 15.66
Average waiting time = (6+4+7)/3 = 17/3 = 5.66
Throughput = 3/30 = 0.1
Processor utilization = (30/30)*100 = 100%
Shortest Remaining Time Next (SRTN): (Shortest Process Next)
This is the pre-emptive version of shortest job first. This permits a process that enters the ready list to pre-empt the running process if the time for the new process (or for its next burst) is less than the remaining time for the running process (or for its current burst). Example:
Consider the set of four processes arrived as per timings described in the table:
Process Arrival Time Processing Time
P1 0 5
P2 1 2
P3 2 5
P4 3 3
At time 0, only process P1 has entered the system, so it is the process that executes. At time 1, process P2 arrives. At that time, process P1 has 4 time units left to execute. At this juncture process 2’s processing time is less compared to the P1 left out time (4 units). So P2 starts executing at time 1. At time 2, process P3 enters the system with the processing time 5 units.Process P2 continues executing as it has the minimum number of time units when compared with P1 and P3. At time 3, process P2 terminates and process P4 enters the system. Of the processes P1, P3 and P4, P4 has the smallest remaining execution time so it starts executing. When process P1 terminates at time 10, process P3 executes. The Gantt chart is shown below:
P1 P2 P4 P1 P3
0 1 3 6 10 15
Turnaround time for each process can be computed by subtracting the time it terminated from the arrival time.
Turn around Time = t(Process Completed) – t(Process Submitted)
The turnaround time for each of the processes is:
P1: 10 – 0 = 10
P2: 3 – 1 = 2
P3: 15 – 2 = 13
P4: 6 – 3 = 3
The average turnaround time is (10+2+13+3) / 4 = 7
The waiting time can be computed by subtracting processing time from turnaround time, yielding the following 4 results for the processes as
P1: 10 – 5 = 5
P2: 2 – 2 = 0
P3: 13 – 5 = 8
P4: 3 – 3 = 0
The average waiting time = (5+0+8+0) /4 = 3.25 milliseconds.
Four jobs executed in 15 time units, so throughput is 15/4 = 3.75 time units/job.
CPU scheduling deals with the problem of deciding which of the processes in the ready queue is to be allocated to the CPU. A major division among scheduling algorithms is that whether they support pre-emptive or non-pre-emptive scheduling discipline.
Pre-emptive scheduling: Pre-emption means the operating system moves a process from running to ready without the process requesting it. An OS implementing these algorithms switches to the processing of a new request before completing the processing of the current request. The preempted request is put back into the list of the pending requests. Its servicing would be resumed sometime in the future when it is scheduled again. Pre-emptive scheduling is more useful in high priority process which requires immediate response. For example, in Real time system the consequence of missing one interrupt could be dangerous.
Round Robin scheduling, priority based scheduling or event driven scheduling and SRTN are considered to be the pre-emptive scheduling algorithms.
Non-Pre-emptive scheduling: A scheduling discipline is non-pre-emptive if once a process has been allotted to the CPU, the CPU cannot be taken away from the process. A non-pre-emptive discipline always processes a scheduled request to its completion. In non-pre-emptive systems, jobs are made to wait by longer jobs, but the treatment of all processes is fairer.
First come First Served (FCFS) and Shortest Job First (SJF), are considered to be the non-preemptive scheduling algorithms.
Round Robin (RR)
Round Robin (RR) scheduling is a pre-emptive algorithm that relates the process that has been waiting the longest. This is one of the oldest, simplest and widely used algorithms. The round robin scheduling algorithm is primarily used in time-sharing and a multi-user system environment where the primary requirement is to provide reasonably good response times and in general to share the system fairly among all system users. Basically the CPU time is divided into time slices.
Each process is allocated a small time-slice called quantum. No process can run for more than one quantum while others are waiting in the ready queue. If a process needs more CPU time to complete after exhausting one quantum, it goes to the end of ready queue to await the next allocation. To implement the RR scheduling, Queue data structure is used to maintain the Queue of Ready processes. A new process is added at the tail of that Queue. The CPU scheduler picks the first process from the ready Queue, Allocate processor for a specified time Quantum. After that time the CPU scheduler will select the next process is the ready Queue.
Consider the following set of process with the processing time given in milliseconds:
Process Processing Time
P1 24
P2 03
P3 03
If we use a time Quantum of 4 milliseconds then process P1 gets the first 4 milliseconds. Since it requires another 20 milliseconds, it is pre-empted after the first time Quantum, and the CPU is given to the next process in the Queue, Process P2. Since process P2 does not need 4 milliseconds, it quits before its time Quantum expires. The CPU is then given to the next process, Process P3 one each process has received 1 time Quantum, the CPU is returned to process P1 for an additional time quantum. The Gantt chart will be:
P1 P2 P3 P1 P1 P1 P1 P1
0 4 7 10 14 18 22 26 30
Process Processing Time Turn around time=t(Process Completed)- t(Process Submitted) Waiting Time=Turn around time – Processing time
P1 24 30 – 0 = 30 30 – 24 = 6
P2 03 7 – 0 = 7 7 – 3 = 4
P3 03 10 – 0 = 10 10 – 3 = 7
Average turn around time = (30+7+10)/3 = 47/3 = 15.66
Average waiting time = (6+4+7)/3 = 17/3 = 5.66
Throughput = 3/30 = 0.1
Processor utilization = (30/30)*100 = 100%
Shortest Remaining Time Next (SRTN): (Shortest Process Next)
This is the pre-emptive version of shortest job first. This permits a process that enters the ready list to pre-empt the running process if the time for the new process (or for its next burst) is less than the remaining time for the running process (or for its current burst). Example:
Consider the set of four processes arrived as per timings described in the table:
Process Arrival Time Processing Time
P1 0 5
P2 1 2
P3 2 5
P4 3 3
At time 0, only process P1 has entered the system, so it is the process that executes. At time 1, process P2 arrives. At that time, process P1 has 4 time units left to execute. At this juncture process 2’s processing time is less compared to the P1 left out time (4 units). So P2 starts executing at time 1. At time 2, process P3 enters the system with the processing time 5 units.Process P2 continues executing as it has the minimum number of time units when compared with P1 and P3. At time 3, process P2 terminates and process P4 enters the system. Of the processes P1, P3 and P4, P4 has the smallest remaining execution time so it starts executing. When process P1 terminates at time 10, process P3 executes. The Gantt chart is shown below:
P1 P2 P4 P1 P3
0 1 3 6 10 15
Turnaround time for each process can be computed by subtracting the time it terminated from the arrival time.
Turn around Time = t(Process Completed) – t(Process Submitted)
The turnaround time for each of the processes is:
P1: 10 – 0 = 10
P2: 3 – 1 = 2
P3: 15 – 2 = 13
P4: 6 – 3 = 3
The average turnaround time is (10+2+13+3) / 4 = 7
The waiting time can be computed by subtracting processing time from turnaround time, yielding the following 4 results for the processes as
P1: 10 – 5 = 5
P2: 2 – 2 = 0
P3: 13 – 5 = 8
P4: 3 – 3 = 0
The average waiting time = (5+0+8+0) /4 = 3.25 milliseconds.
Four jobs executed in 15 time units, so throughput is 15/4 = 3.75 time units/job.
Question 6:
i) What
are the main differences between capabilities lists and access lists? Explain
through examples.
(10 Marks)
Answer :
The access matrix model for computer protection is based on abstraction of operating system structures. Because of its simplicity and generality, it allows a variety of implementation techniques, as has been widely used.
There are three principal components in the access matrix model:
• A set of passive objects,
• A set of active subjects, which may manipulate the objects,
• A set of rules governing the manipulation of objects by subjects.
Objects are typically files, terminals, devices, and other entities implemented by an operating system. A subject is a process and a domain (a set of constraints within which the process may access certain objects). It is important to note that every subject is also an object; thus it may be read or otherwise manipulated by another subject. The access matrix is a rectangular array with one row per subject and one column per object. The entry for a particular row and column reflects the mode of access between the corresponding subject and object. The mode of access allowed depends on the type of the object and on the functionality of the system; typical modes are read, write, append, and execute.
All accesses to objects by subjects are subject to some conditions laid down by an enforcement mechanism that refers to the data in the access matrix. This mechanism, called a reference monitor, rejects any accesses (including improper attempts to alter the access matrix data) that are not allowed by the current protection state and rules. References to objects of a given type must be validated by the monitor for that type. While implementing the access matrix, it has been observed that the access matrix tends to be very sparse if it is implemented as a two-dimensional array.
Consequently, implementations that maintain protection of data tend to store them either row wise, keeping with each subject a list of objects and access modes allowed on it; or column wise, storing with each object a list of those subjects that may access it and the access modes allowed on each. The former approach is called the capability list approach and the latter is called the access control list approach.
In general, access control governs each user’s ability to read, execute, change, or delete information associated with a particular computer resource. In effect, access control works at two levels: first, to grant or deny the ability to interact with a resource, and second, to control what kinds of operations or activities may be performed on that resource. Such controls are managed by an access control system.
The access matrix model for computer protection is based on abstraction of operating system structures. Because of its simplicity and generality, it allows a variety of implementation techniques, as has been widely used.
There are three principal components in the access matrix model:
• A set of passive objects,
• A set of active subjects, which may manipulate the objects,
• A set of rules governing the manipulation of objects by subjects.
Objects are typically files, terminals, devices, and other entities implemented by an operating system. A subject is a process and a domain (a set of constraints within which the process may access certain objects). It is important to note that every subject is also an object; thus it may be read or otherwise manipulated by another subject. The access matrix is a rectangular array with one row per subject and one column per object. The entry for a particular row and column reflects the mode of access between the corresponding subject and object. The mode of access allowed depends on the type of the object and on the functionality of the system; typical modes are read, write, append, and execute.
All accesses to objects by subjects are subject to some conditions laid down by an enforcement mechanism that refers to the data in the access matrix. This mechanism, called a reference monitor, rejects any accesses (including improper attempts to alter the access matrix data) that are not allowed by the current protection state and rules. References to objects of a given type must be validated by the monitor for that type. While implementing the access matrix, it has been observed that the access matrix tends to be very sparse if it is implemented as a two-dimensional array.
Consequently, implementations that maintain protection of data tend to store them either row wise, keeping with each subject a list of objects and access modes allowed on it; or column wise, storing with each object a list of those subjects that may access it and the access modes allowed on each. The former approach is called the capability list approach and the latter is called the access control list approach.
In general, access control governs each user’s ability to read, execute, change, or delete information associated with a particular computer resource. In effect, access control works at two levels: first, to grant or deny the ability to interact with a resource, and second, to control what kinds of operations or activities may be performed on that resource. Such controls are managed by an access control system.
ii) What
is the Kernel of an operating system? What functions are normally performed by the
Kernel? Gives several reasons why it is effective to design micro Kernel.
(10 Marks)
Answer :
The operating system, referred to in UNIX as the kernel, interacts directly with the hardware and provides the services to the user programs. These user programs don’t need to know anything about the hardware. They just need to know how to interact with the kernel and it’s up to the kernel to provide the desired service. One of the big appeals of UNIX to programmers has been that most well written user programs are independent of the underlying hardware, making them readily portable to new systems.
User programs interact with the kernel through a set of standard system calls. These system calls request services to be provided by the kernel. Such services would include accessing a file: open close, read, write, link, or execute a file; starting or updating accounting records; changing ownership of a file or directory; changing to a new directory; creating, suspending, or killing a process; enabling access to hardware devices; and setting limits on system resources.
UNIX is a multi-user, multi-tasking operating system. You can have many users logged into a system simultaneously, each running many programs. It is the kernel’s job to keep each process and user separate and to regulate access to system hardware, including CPU, memory, disk and other I/O devices.
Operating systems can be either monolithic (e.g., UNIX and Windows) or modular (e.g., Mach and Windows NT). A modular operating system is called a micro kernel. A micro-kernel OS has a small minimalist kernel that includes as little functionality as possible.
The operating system, referred to in UNIX as the kernel, interacts directly with the hardware and provides the services to the user programs. These user programs don’t need to know anything about the hardware. They just need to know how to interact with the kernel and it’s up to the kernel to provide the desired service. One of the big appeals of UNIX to programmers has been that most well written user programs are independent of the underlying hardware, making them readily portable to new systems.
User programs interact with the kernel through a set of standard system calls. These system calls request services to be provided by the kernel. Such services would include accessing a file: open close, read, write, link, or execute a file; starting or updating accounting records; changing ownership of a file or directory; changing to a new directory; creating, suspending, or killing a process; enabling access to hardware devices; and setting limits on system resources.
UNIX is a multi-user, multi-tasking operating system. You can have many users logged into a system simultaneously, each running many programs. It is the kernel’s job to keep each process and user separate and to regulate access to system hardware, including CPU, memory, disk and other I/O devices.
Operating systems can be either monolithic (e.g., UNIX and Windows) or modular (e.g., Mach and Windows NT). A modular operating system is called a micro kernel. A micro-kernel OS has a small minimalist kernel that includes as little functionality as possible.
------------------------------------------
Course Code : MCS-042
Course Title : Data Communication and Computer
Networks
Assignment Number : MCA(4)/042/Assign/09
Maximum Marks : 100
Weightage : 25%
Last Date of Submission : 15th
October, 2009 (for July,2009 session)
15th
April, 2010 (for January, 2010 session)
This assignment has five
questions, which carries 80 marks. Answer all questions. Rest 20 marks are for
viva voce. You may use illustrations and
diagrams to enhance the explanations.
Please go through the guidelines regarding assignments given in the
Programme Guide for the format of presentation. Answer to each part of the
question should be confined to about 300 words.
Question 1:
i) What are the Nyquist and the Shannon limits
on the channel capacity? Elaborate through examples.
(8 Marks)
In information theory, the Shannon–Hartley
theorem is an application of the noisy channel coding theorem to the archetypal
case of a continuous-time analog communications channel subject to Gaussian
noise. The theorem establishes Shannon's channel capacity for such a communication
link, a bound on the maximum amount of error-free digital data (that is,
information) that can be transmitted with a specified
bandwidth in the presence of the noise interference, under the assumption that the signal power is bounded and the Gaussian noise process is characterized by a known power or power spectral density. The law is named after Claude Shannon and Ralph Hartley
Statement of the theorem
Considering all possible multi-level and multi-phase encoding techniques, the Shannon–Hartley theorem states that the channel capacity C, meaning the theoretical tightest upper bound on the information rate (excluding error correcting codes) of clean (or arbitrarily low bit error rate) data that can be sent with a given average signal power S through an analog communication channel subject to additive white Gaussian noise of power N, is:
C = B log2(1 + S/N)
where
C is the channel capacity in bits per second;
B is the bandwidth of the channel in hertz (passband bandwidth in case of a modulated signal);
S is the total received signal power over the bandwidth (in case of a modulated signal, often denoted C, i.e. modulated carrier), measured in watt or volt2;
N is the total noise or interference power over the bandwidth, measured in watt or volt2; and
S/N is the signal-to-noise ratio (SNR) or the carrier-to-noise ratio (CNR) of the communication signal to the Gaussian noise interference expressed as a linear power ratio (not as logarithmic decibels).
Historical development
During the late 1920s, Harry Nyquist and Ralph Hartley developed a handful of fundamental ideas related to the transmission of information, particularly in the context of the telegraph as a communications system. At the time, these concepts were powerful breakthroughs individually, but they were not part of a comprehensive theory. In the 1940s, Claude Shannon developed the concept of channel capacity, based in part on the ideas of Nyquist and Hartley, and then formulated a complete theory of information and its transmission.
Nyquist rate
In 1927, Nyquist determined that the number of independent pulses that could be put through a telegraph channel per unit time is limited to twice the bandwidth of the channel. In symbols, where fp is the pulse frequency (in pulses per second) and B i s the bandwidth (in hertz). The quantity 2B later came to be called the Nyquist rate, and transmitting at the limiting pulse rate of 2B pulses per second as signalling at the Nyquist rate. Nyquist published his results in 1928 as part of his paper "Certain topics in Telegraph Transmission Theory."
bandwidth in the presence of the noise interference, under the assumption that the signal power is bounded and the Gaussian noise process is characterized by a known power or power spectral density. The law is named after Claude Shannon and Ralph Hartley
Statement of the theorem
Considering all possible multi-level and multi-phase encoding techniques, the Shannon–Hartley theorem states that the channel capacity C, meaning the theoretical tightest upper bound on the information rate (excluding error correcting codes) of clean (or arbitrarily low bit error rate) data that can be sent with a given average signal power S through an analog communication channel subject to additive white Gaussian noise of power N, is:
C = B log2(1 + S/N)
where
C is the channel capacity in bits per second;
B is the bandwidth of the channel in hertz (passband bandwidth in case of a modulated signal);
S is the total received signal power over the bandwidth (in case of a modulated signal, often denoted C, i.e. modulated carrier), measured in watt or volt2;
N is the total noise or interference power over the bandwidth, measured in watt or volt2; and
S/N is the signal-to-noise ratio (SNR) or the carrier-to-noise ratio (CNR) of the communication signal to the Gaussian noise interference expressed as a linear power ratio (not as logarithmic decibels).
Historical development
During the late 1920s, Harry Nyquist and Ralph Hartley developed a handful of fundamental ideas related to the transmission of information, particularly in the context of the telegraph as a communications system. At the time, these concepts were powerful breakthroughs individually, but they were not part of a comprehensive theory. In the 1940s, Claude Shannon developed the concept of channel capacity, based in part on the ideas of Nyquist and Hartley, and then formulated a complete theory of information and its transmission.
Nyquist rate
In 1927, Nyquist determined that the number of independent pulses that could be put through a telegraph channel per unit time is limited to twice the bandwidth of the channel. In symbols, where fp is the pulse frequency (in pulses per second) and B i s the bandwidth (in hertz). The quantity 2B later came to be called the Nyquist rate, and transmitting at the limiting pulse rate of 2B pulses per second as signalling at the Nyquist rate. Nyquist published his results in 1928 as part of his paper "Certain topics in Telegraph Transmission Theory."
ii) Differentiate between the followings:
a)
FDM and TDM
b)
Circuit
switching and packet switching
c)
Virtual circuit
and diagram
d)
Stop and wait
protocol and sliding window protocol
(12
Marks)
a) FDM and TDM
The resource allocation method is the most important factor for the efficient design of SubMAP. Particularly, the multiplexing between data regions and control regions is a key hardware out there to support. Second, and perhaps more or at least very important, it could well turn up on the test. If one question stands between you and passing, don’t make this the one you miss. In principle, circuit switching and packet switching both are used in high-capacity networks. In circuit-switched networks, network resources are static, set in “copper” if you will, from the sender to receiver before the start of the transfer, thus creating a “circuit”. The resources remain dedicated to the circuit during the entire transfer and the entire message follows the same path. In
packet-switched networks, the message is broken into packets, each of which can take a different route to the destination where the packets are recompiled into the original message. All the above can be handled by a router or a switch but much of IT today is going toward flat switched networks. So when we’re talking about circuit switching or packet switching, we are more and more talking about doing it on a switch.
Switched Networks
First, let’s be sure we understand what we mean by a switched network. A switched network goes through a switch instead of a router. This actually is the way most networks are headed, toward flat switches on VLANs instead of routers. Still, it’s not always easy to tell a router from a switch. It’s commonly believed that the difference between a switched network and a routed network is simple binary opposition. T’ain’t so. A router operates at Layer 3 of the OSI Model and can create and connect several logical networks, including those of different network topologies, such as Ethernet and Token Ring. A router will provide multiple paths (compared to only one on a bridge) between segments and will map nodes on a segment and the connecting paths with a routing protocol and internal routing tables. Being a Layer 3 device, the router uses the destination IP address to decide where a frame should go. If the destination IP address is on a segment directly connected to the router, then the router will forward the frame out the appropriate port to that segment. If not, the router will search its routing table for the correct destination, again, using that IP address.
Having talked about a router as being a Layer 3 device, think about what I’m about to say next as a general statement. I know there are exceptions, namely the Layer 3 switch. We’re not going to get into that, not in this article.
A switch is very like a bridge in that is usually a layer 2 device that looks to MAC addresses to determine where data should be directed. A switch has other applications in common with a bridge. Like a bridge, a switch will use transparent and source-route methods to move data and Spanning Tree Protocol ( STP) to avoid loops. However, switches are superior to bridges because they provide greater port density and they
can be configured to make more intelligent decisions about where data goes.
The three most common switch methods are:
1. Cut-through - Streams data so that the first part of a packet exits the switch before the rest of the packet has finished entering the switch, typically within the first 12 bytes of an Ethernet frame.
2. Store-and-Forward - The entire frame is copied into the switch's memory buffer and it stays there while the switch processes the Cyclical Redundancy Check CRC) to look for errors in the frame. If the frame contains no errors, it will be forwarded. If a frame contains an error, it will be dropped. Obviously, this method has higher latency than cut-through but there will be no fragments or bad frames taking up bandwidth.
3. Fragment-free Switching - Think of this as a hybrid of cut-through and store-and-forward. The switch reads only the first 64 bytes of the frame into buffer
c) Virtual Circuit and Diagram
Differences between datagram and virtual circuit networks
There are a number of important differences between virtual circuit and datagram networks. The choice strongly impacts complexity of the different types of node. Use of datagram’s between intermediate nodes allows relatively simple protocols at this level, but at the expense of making the end (user) nodes more complex when end-to-end virtual circuit service is desired.
The Internet transmits data grams between intermediate nodes using IP. Most Internet users need additional functions such as end-to-end error and sequence control to give a reliable service (equivalent to that provided by virtual circuits). This reliability may be provided by the Transmission Control Protocol (TCP) which is used end-to-end across the Internet, or by applications such as the trivial file transfer protocol (tftp) running on top of the User Datagram Protocol (UDP).
d) Stop and Wait Protocol and Sliding Window Protocol
This experiment will bring out the correct choice of the packet sizes for transmission in noisy channels.Open two sliding window (S/W) applications, each in one computer. Assign Node Id 1 as receiver and Node Id 0 as sender. Conduct the experiment for 200 secs. Set the link rate to be 8kbps. Set the protocol to CSMA/CD.Set the No. of Packets (Window size) to 1 in both nodes (because Stop and Wait protocol is a window size-1 algorithm). Make sure the No. of Nodes is set to 2 and the Inter Packet delay (IPD) in both the nodes is set to 0. This makes sure no delay is introduced in the network other than the transmission delay. Set the Tx/Rx Mode to be Promiscous mode and the direction as sender or Receiver accordingly. Set BER to 0 and run the experiment. Find out the size of the transmitted packets and the acknowledgement packets received. Calculate the overhead involved in the transmitted packets for different packet sizes. Choose packet sizes 10 ..100 bytes in multiples of 10. Now set BER to 10-3 and perform the experiment. Give timeout as 1000ms. Calculate the throughputs. Perform the previous steps now for a BER of 10-4 for packet sizes (100..900) bytes in steps of 100 and calculate the throughputs. Packet sizes are chosen longer, as the BER is less. Give larger timeout as packets are longer(say, 2000ms). Plot throughput vs packet size curves and find out the optimum packet size for the different BERs .
Sliding Window Protocol
This experiment will bring out the necessity of increasing the transmitter and receiver window sizes and the correct choice of the window size in a delay network.
1. Set up the same configuration as for the previous experiment.
2. Set BER to 0 and fix the packet size at 100 bytes.
3. Set IPD at the sender constantly at 20 ms and the IPD at the receiver to vary between 40 to 190 ms (in steps of 50). This setting simulates various round-trip delays in the network.
4. Change the Window sizes from 1 to 5 in both the nodes together. Give large timeout, 10000ms, as this will make sure that there are very few re-transmissions. Now perform the experiment.
5. Plot the throughput vs Window Sizes for different IPDs and find out the optimum window size for different delays.
The resource allocation method is the most important factor for the efficient design of SubMAP. Particularly, the multiplexing between data regions and control regions is a key hardware out there to support. Second, and perhaps more or at least very important, it could well turn up on the test. If one question stands between you and passing, don’t make this the one you miss. In principle, circuit switching and packet switching both are used in high-capacity networks. In circuit-switched networks, network resources are static, set in “copper” if you will, from the sender to receiver before the start of the transfer, thus creating a “circuit”. The resources remain dedicated to the circuit during the entire transfer and the entire message follows the same path. In
packet-switched networks, the message is broken into packets, each of which can take a different route to the destination where the packets are recompiled into the original message. All the above can be handled by a router or a switch but much of IT today is going toward flat switched networks. So when we’re talking about circuit switching or packet switching, we are more and more talking about doing it on a switch.
Switched Networks
First, let’s be sure we understand what we mean by a switched network. A switched network goes through a switch instead of a router. This actually is the way most networks are headed, toward flat switches on VLANs instead of routers. Still, it’s not always easy to tell a router from a switch. It’s commonly believed that the difference between a switched network and a routed network is simple binary opposition. T’ain’t so. A router operates at Layer 3 of the OSI Model and can create and connect several logical networks, including those of different network topologies, such as Ethernet and Token Ring. A router will provide multiple paths (compared to only one on a bridge) between segments and will map nodes on a segment and the connecting paths with a routing protocol and internal routing tables. Being a Layer 3 device, the router uses the destination IP address to decide where a frame should go. If the destination IP address is on a segment directly connected to the router, then the router will forward the frame out the appropriate port to that segment. If not, the router will search its routing table for the correct destination, again, using that IP address.
Having talked about a router as being a Layer 3 device, think about what I’m about to say next as a general statement. I know there are exceptions, namely the Layer 3 switch. We’re not going to get into that, not in this article.
A switch is very like a bridge in that is usually a layer 2 device that looks to MAC addresses to determine where data should be directed. A switch has other applications in common with a bridge. Like a bridge, a switch will use transparent and source-route methods to move data and Spanning Tree Protocol ( STP) to avoid loops. However, switches are superior to bridges because they provide greater port density and they
can be configured to make more intelligent decisions about where data goes.
The three most common switch methods are:
1. Cut-through - Streams data so that the first part of a packet exits the switch before the rest of the packet has finished entering the switch, typically within the first 12 bytes of an Ethernet frame.
2. Store-and-Forward - The entire frame is copied into the switch's memory buffer and it stays there while the switch processes the Cyclical Redundancy Check CRC) to look for errors in the frame. If the frame contains no errors, it will be forwarded. If a frame contains an error, it will be dropped. Obviously, this method has higher latency than cut-through but there will be no fragments or bad frames taking up bandwidth.
3. Fragment-free Switching - Think of this as a hybrid of cut-through and store-and-forward. The switch reads only the first 64 bytes of the frame into buffer
c) Virtual Circuit and Diagram
Differences between datagram and virtual circuit networks
There are a number of important differences between virtual circuit and datagram networks. The choice strongly impacts complexity of the different types of node. Use of datagram’s between intermediate nodes allows relatively simple protocols at this level, but at the expense of making the end (user) nodes more complex when end-to-end virtual circuit service is desired.
The Internet transmits data grams between intermediate nodes using IP. Most Internet users need additional functions such as end-to-end error and sequence control to give a reliable service (equivalent to that provided by virtual circuits). This reliability may be provided by the Transmission Control Protocol (TCP) which is used end-to-end across the Internet, or by applications such as the trivial file transfer protocol (tftp) running on top of the User Datagram Protocol (UDP).
d) Stop and Wait Protocol and Sliding Window Protocol
This experiment will bring out the correct choice of the packet sizes for transmission in noisy channels.Open two sliding window (S/W) applications, each in one computer. Assign Node Id 1 as receiver and Node Id 0 as sender. Conduct the experiment for 200 secs. Set the link rate to be 8kbps. Set the protocol to CSMA/CD.Set the No. of Packets (Window size) to 1 in both nodes (because Stop and Wait protocol is a window size-1 algorithm). Make sure the No. of Nodes is set to 2 and the Inter Packet delay (IPD) in both the nodes is set to 0. This makes sure no delay is introduced in the network other than the transmission delay. Set the Tx/Rx Mode to be Promiscous mode and the direction as sender or Receiver accordingly. Set BER to 0 and run the experiment. Find out the size of the transmitted packets and the acknowledgement packets received. Calculate the overhead involved in the transmitted packets for different packet sizes. Choose packet sizes 10 ..100 bytes in multiples of 10. Now set BER to 10-3 and perform the experiment. Give timeout as 1000ms. Calculate the throughputs. Perform the previous steps now for a BER of 10-4 for packet sizes (100..900) bytes in steps of 100 and calculate the throughputs. Packet sizes are chosen longer, as the BER is less. Give larger timeout as packets are longer(say, 2000ms). Plot throughput vs packet size curves and find out the optimum packet size for the different BERs .
Sliding Window Protocol
This experiment will bring out the necessity of increasing the transmitter and receiver window sizes and the correct choice of the window size in a delay network.
1. Set up the same configuration as for the previous experiment.
2. Set BER to 0 and fix the packet size at 100 bytes.
3. Set IPD at the sender constantly at 20 ms and the IPD at the receiver to vary between 40 to 190 ms (in steps of 50). This setting simulates various round-trip delays in the network.
4. Change the Window sizes from 1 to 5 in both the nodes together. Give large timeout, 10000ms, as this will make sure that there are very few re-transmissions. Now perform the experiment.
5. Plot the throughput vs Window Sizes for different IPDs and find out the optimum window size for different delays.
Question 2:
i) Compare
the features of different 10 Mbps, 100 Mbps and 1000 Mbps Ethernet
technologies.
(5 Marks)
----->
10-Mbps Ethernet—10Base-T
10Base-T
provides Manchester-encoded 10-Mbps bit-serial communication over two
unshielded twisted-pair cables. Although the standard was designed to support
transmission over common telephone cable, the more typical link configuration
is to use two pair of a four-pair Category 3 or 5 cable, terminated at each NIC
with an 8-pin RJ-45 connector (the MDI), as shown in Figure 7-15. Because each
active pair is configured as a simplex link where transmission is in one
direction only, the 10Base-T physical layers can support either half-duplex or
full-duplex operation.

Although 10Base-T may be considered essentially obsolete in some
circles, it is included here because there are still many 10Base-T Ethernet
networks, and because full-duplex operation has given 10BaseT an extended life.
10Base-T was also the first
Ethernet version to include a link integrity test to determine the health of
the link. Immediately after powerup, the PMA transmits a normal link pulse
(NLP) to tell the NIC at the other end of the link that this NIC wants to
establish an active link connection:
• If the NIC at the other end of the link is
not powered up, this NIC continues sending an NLP about once every 16 ms until
it receives a response.
If the NIC at the other end of the link is
not powered up, this NIC continues sending an NLP about once every 16 ms until
it receives a response.
100 Mbps—Fast Ethernet
Increasing
the Ethernet transmission rate by a factor of ten over 10Base-T was not a
simple task, and the effort resulted in the development of three separate
physical layer standards for 100 Mbps over UTP cable: 100Base-TX and 100Base-T4
in 1995, and 100Base-T2 in 1997. Each was defined with different encoding
requirements and a different set of media-dependent sublayers, even though
there is some overlap in the link cabling. Table 7-2 compares the physical
layer characteristics of 10Base-T to the various 100Base versions.
1 One baud =
one transmitted symbol per second, where the transmitted symbol may contain the
equivalent value of 1 or more binary bits.
Although
not all three 100-Mbps versions were successful in the marketplace, all three
have been discussed in the literature, and all three did impact future designs.
As such, all three are important to consider here.
100Base-X
100Base-X was designed to support transmission over either two
pairs of Category 5 UTP copper wire or two strands of optical fiber. Although
the encoding, decoding, and clock recovery procedures are the same for both
media, the signal transmission is different—electrical pulses in copper and
light pulses in optical fiber. The signal transceivers that were included as
part of the PMA function in the generic logical model of Figure 7-14 were
redefined as the separate physical media-dependent (PMD) sublayers shown in
Figure 7-16.

The 100Base-X encoding procedure is based on the earlier FDDI
optical fiber physical media-dependent and FDDI/CDDI copper twisted-pair
physical media-dependent signaling standards developed by ISO and ANSI. The
100Base-TX physical media-dependent sublayer (TP-PMD) was implemented with CDDI
semiconductor transceivers and RJ-45 connectors; the fiber PMD was implemented
with FDDI optical transceivers and the Low Cost Fibre Interface Connector
(commonly called the duplex SC connector).
The 4B/5B encoding procedure is the same as the encoding procedure
used by FDDI, with only minor adaptations to accommodate Ethernet frame
control. Each 4-bit data nibble (representing half of a data byte) is mapped
into a 5-bit binary code-group that is transmitted bit-serial over the link.
The expanded code space provided by the 32 5-bit
code-groups allow separate assignment for the following:
code-groups allow separate assignment for the following:
•Four control code-groups that are transmitted
as code-group pairs to indicate the start-of-stream delimiter (SSD) and the
end-of-stream delimiter (ESD). Each MAC frame is "encapsulated" to
mark both the beginning and end of the frame. The first byte of preamble is
replaced with SSD code-group pair that precisely identifies the frame's
code-group boundaries. The ESD code-group pair is appended after the frame's
FCS field.
•A special IDLE code-group that is
continuously sent during interframe gaps to maintain continuous synchronization
between the NICs at each end of the link. The receipt of IDLE is interpreted to
mean that the link is quiet.
•Eleven invalid code-groups that are not
intentionally transmitted by a NIC (although one is used by a repeater to
propagate receive errors). Receipt of any invalid code-group will cause the
incoming frame to be treated as an invalid frame.
Figure 7-17 shows how a MAC frame
is encapsulated before being transmitted as a 100Base-X code-group stream.
----->
ii) Explain
the basic operation of collision detection in Ethernet.
(5 Marks)
Collision detection is used to improve CSMA performance by terminating
transmission as soon as a collision is detected, and reducing the probability
of a second collision on retry.
Methods for collision detection are media dependent, but on an
electrical bus such as Ethernet, collisions can be detected by comparing
transmitted data with received data. If they differ, another transmitter is
overlaying the first transmitter's signal (a collision), and transmission
terminates immediately. A jam signal is sent which will cause all transmitters
to back off by random intervals, reducing the probability of a collision when
the first retry is attempted.
In our conversation, we can handle this situation gracefully. We
both hear the other speak at the same time we are speaking, so we can stop to
give the other person a chance to go on. Ethernet nodes also listen to the
medium while they transmit to ensure that they are the only station
transmitting at that time. If the stations hear their own transmission
returning in a garbled form, as would happen if some other station had begun to
transmit its own message at the same time, then they know that a collision
occurred. A single Ethernet segment is sometimes called a collision
domain because no
two stations on the segment can transmit at the same time without causing a
collision. When stations detect a collision, they cease transmission, wait a
random amount of time, and attempt to transmit when they again detect silence
on the medium.
The random pause and retry is an
important part of the protocol. If two stations collide when transmitting once,
then both will need to transmit again. At the next appropriate chance to
transmit, both stations involved with the previous collision will have data
ready to transmit. If they transmitted again at the first opportunity, they
would most likely collide again and again indefinitely. Instead, the random
delay makes it unlikely that any two stations will collide more than a few
times in a row.
iii) Compare the advantages of fibre optics over copper wire and coaxial
cable.
(5 Marks)
Fiber Optic Benefits and Fiber Optic Advantages
Fiber-optic systems use pulses of light traveling through an
optical fiber to transmit data. This method offers many advantages over copper
wire, some of which are not available with other technology:
§ Complete input/output electrical isolation
§ No electromagnetic interference (EMI) susceptibility or
radiation along the transmission media
§ Broad bandwidth over a long distance
§ Light-weight, small-diameter cables
§ Equal to the cost of copper wire and connectors (except when copper
wire is already installed)
So
let’s explain the fiber optic benefits and advantages in detail below:
1.
Electromagnetic Interference (EMI)
Because optical fiber transmits light rather than electrons, it
neither radiates EM (electromagnetic) fields nor is it susceptible to any EM
fields surrounding it. This is important in a number of applications:
§ Industrial control, where cables run along factory floors in
proximity to electrically noisy machinery. The optical medium permits the
control signals to be carried error-free through the electrically noisy
environment.
§ Telecommunications equipment manufacturers use optical fiber
because it eliminates cross talk between the telecommunication lines.
§ Financial institutions and gaming equipment manufacturers require
data security. Tapping into a fiber cable without being detected is extremely
difficult.
2.
High Bandwidth
Optical fiber has a relatively high bandwidth in comparison to
other transmission media. This permits much longer transmission distances and
much higher signal rates than most media. For example, all undersea long-haul
telecommunications cable is fiber-optic.
This technology is allowing worldwide communications (voice,
video and data) to be available mainstream. With new technologies, such as VCSEL
transmitters, parallel optics and wavelength division multiplexing (WDM),
services such as video-on-demand and video conferencing will be available to
most homes in the near future.
3.
Voltage Isolation and Voltage Insulation
Fiber isolates two different voltage potentials. and insulates
in high-voltage areas. For example, it will eliminate errors due to ground-loop
potential differences and is ideal for data transmission in areas subject to
frequent electrical storms, and presents no hazard to the field installer.
4.
Weight and Diameter
A 100 meter coaxial cable transmitting 500 megabits of data per
unit time is about 800 percent heavier than a plastic fiber cable and about 700
percent heavier than a hard-clad silica cable, all of equal length and transmitting
at the same data rate.
The relative diameters of various types of fiber cable and
coaxial copper cable for the same distance and data rate are shown in the
illustration below.
BRIEF OVER VIEW OF FIBER OPTIC CABLE ADVANTAGES OVER COPPER:
• SPEED: Fiber optic networks operate at high speeds - up into the gigabits• BANDWIDTH: large carrying capacity
• DISTANCE: Signals can be transmitted further without needing to be "refreshed" or strengthened.
• RESISTANCE: Greater resistance to electromagnetic noise such as radios, motors or other nearby cables.
• MAINTENANCE: Fiber optic cables costs much less to maintain.
No comments:
Post a Comment